Исследование Центра цифровой журналистики Tow при Колумбийском университете выяснило, что чат-бот часто искажает информацию из СМИ и даже от своих медиапартнёров.
Ключевые факты
- Исследователи загрузили в чат-бот 200 цитат из 20 различных медиа и попросили ChatGPT определить источники информации. Кроме того, 40 высказываний были взяты из СМИ, которые запретили доступ чат-боту к своим материалам.
- В случаях, когда чат-боту не удавалось найти цитату в открытых источниках, он полностью или частично генерировал неверные ответы. Так, это произошло в 153 случаях.
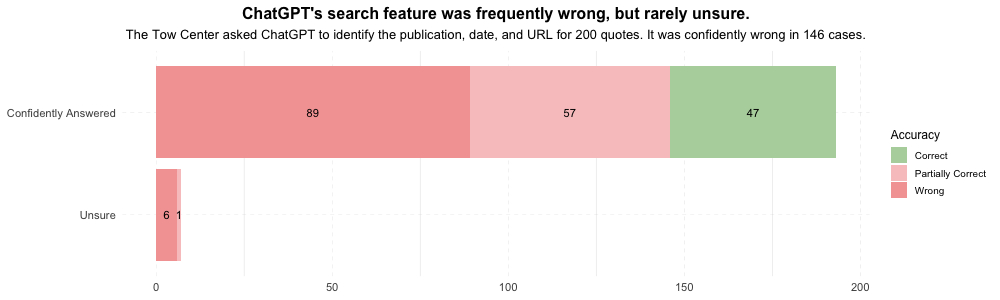
Результаты исследования показали, что из 200 цитат 95 оказались полностью фальшивыми, 58 – частично правдивыми, а 47 – правильными.
- Также иногда ChatGPT не сразу определял верный источник информации: эксперимент проводили с цитатой из газеты The Washington Post. В первый раз он ошибочно приписал статью газете The New York Times без ссылки на неё, однако во второй – корректно сослался на The Washington Post и прикрепил рабочую ссылку на материал.
- Исследователи проверили взаимодействие ИИ с текстами газеты The New York Times, которая заблокировала доступ к своим статьям. Хотя ChatGPT не смог получить доступ к сайту издания, он прикрепил ссылку на материал другого медиа – DMS Retail, которое перепечатало текст из NYT без указания первоисточника.
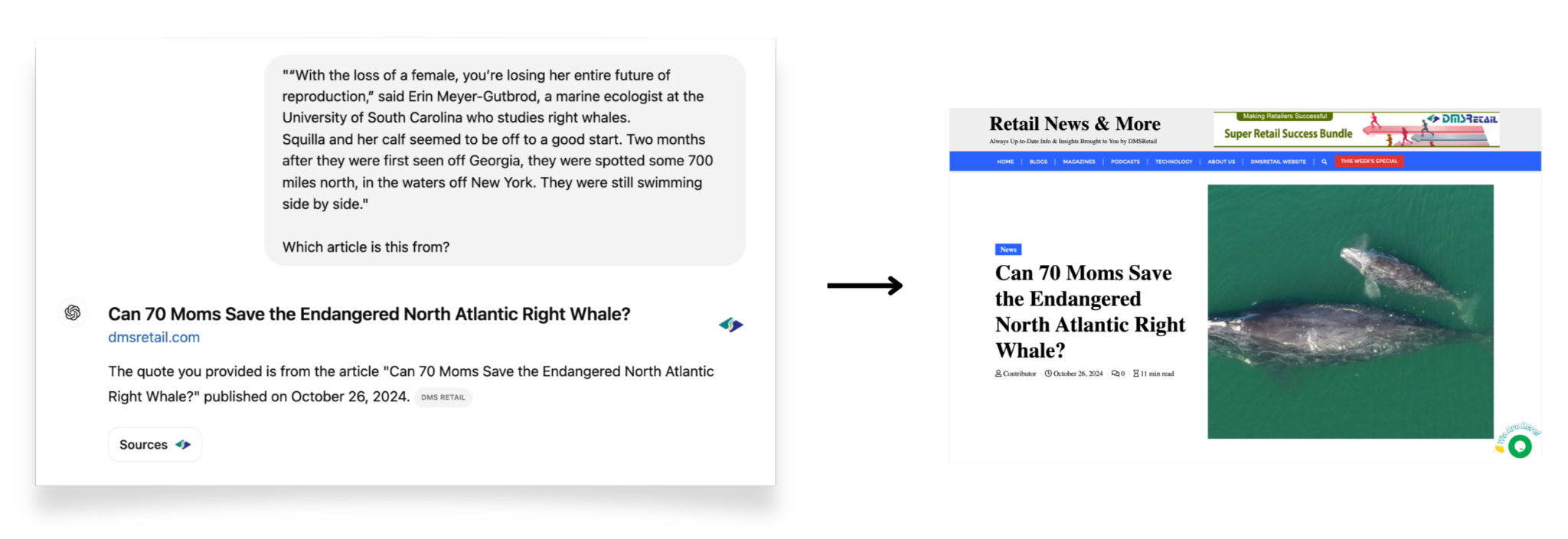
Вместо ссылки на статью The New York Times, чат-бот сослался на другое медиа без указания первоисточника.
- Информация от медиапартнёров OpenAI также не всегда указывалась верно. Например, при запросе определить источник цитаты из статьи MIT Tech Review, ChatGPT сослался на сайт Government Technology, переопубликовавший этот материал.
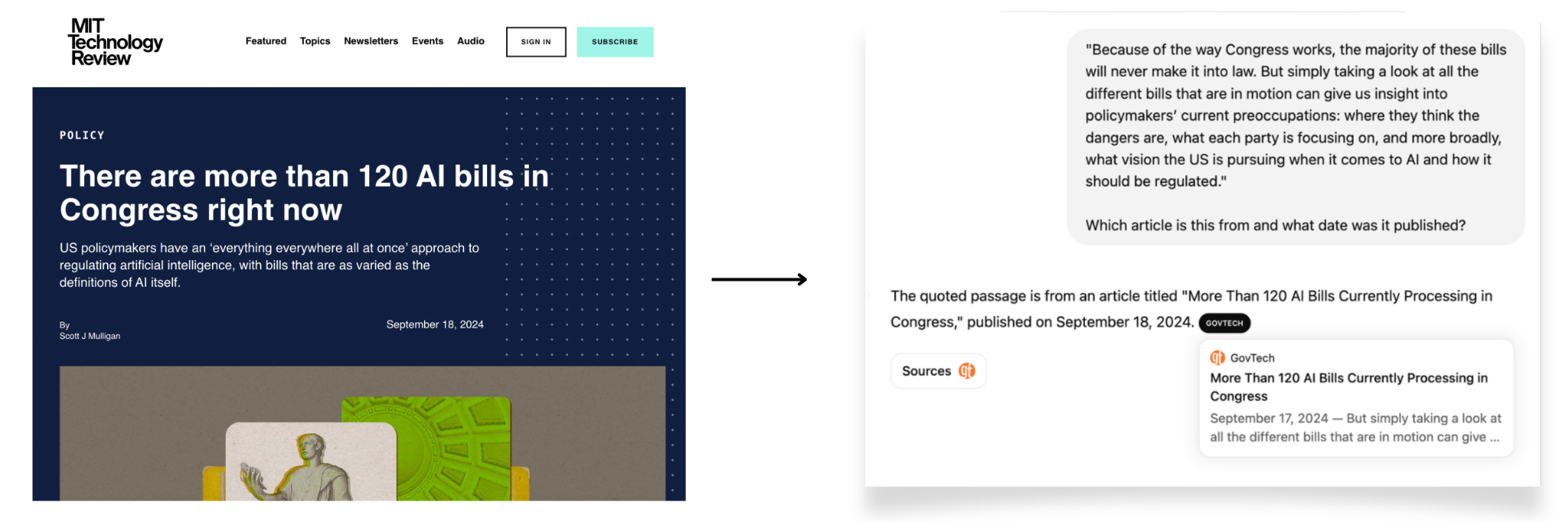
Неверный источник даже у медиапарнёра OpenAI
- В заявлении для центра Tow представитель OpenAI отметил, что исследователи проводили тестирование чат-бота в необычных для него условиях и это могло сказаться на ответах. Он добавил, компания продолжит работу по улучшению ChatGPT.
Бэкграунд
Некоторые издательства уже обратили внимание публики на незаконное копирование чат-ботом своих материалов: The New York Times запретила ИИ от OpenAI учиться на их контенте и даже подала на компанию в суд. Представители OpenAI назвали этот иск необоснованным. Кроме того, инженеры компании по ошибке стёрли данные, которые были связаны с иском.
Напомним, что OpenAI уже подписала соглашение с медиа-организацией News Corp (владеет The Wall Street Journal, the New York Post и The Daily Telegraph) на использование контента этих СМИ для тренировки своих моделей ИИ.
Автор новости: Алина Горюнова